boothrflow: Local-First Voice Dictation That Stays on Your Machine
The best voice-dictation tools on the market right now ship your audio to someone else’s GPU. Wispr Flow, Superwhisper, Aqua, AudioPen — they’re all good products, and they all live on the assumption that you don’t mind a third party hearing every word you say into your microphone. For a lot of what I dictate, that’s a non-starter.
So I built boothrflow: a push-to-talk dictation tool that runs entirely on your machine. Hold a hotkey, talk, release, and the cleaned-up text pastes into whatever you were focused on. No network call. No vendor with a transcript log. Just Whisper or Parakeet doing STT, a local LLM doing cleanup, and SQLite holding the history.
It’s pre-alpha — the hot path is solid on macOS and Windows, but it’s not signed, not packaged, and not for non-developers yet. The post below is the technical state of things and where it’s headed.
Why local-first, specifically
I’m a huge privacy advocate — have been since I was young. My first ever donation was to the EFF. For me, Dictation is a rambling, unstructured, and unrefined stream of consciousness that in raw form is never meant to be shared. In my business (we’re a private equity shop registered as an RIA), privacy comes in two flavors in order to remain compliant with our SEC rules: (1) log everything offsite with a trusted third-party provider or (2) log nothing, as there will be nothing to breach or steal.
Generally, we choose (2). It is a zero-trust mechanism that presumes breach, so what boothrflow does is keep everything hyper-local to your localized security schema — and allows for privacy modes that don’t even use the local operating system accessibility features that could be further used for leveraged attacks. Many other industries could find themselves in similar positions:
- Legal and medical: an attorney dictating notes on a deposition, a doctor talking through a differential — both have explicit duties not to transmit patient or client content to third parties without consent.
- Founders and execs: any voice memo about an acquisition, a hire, a fundraise, or a co-founder dispute is material non-public information from the moment you say it out loud. These are open for discovery, but a local on-disk and encrypted SQLite database with a password, at least in the U.S., cannot be forced to be shared for discovery.
- Journalists: source protection is the whole job; piping a phone-call transcript through a US-based SaaS subpoenable in 30 days is the opposite of that.
- Security and infrastructure: SREs dictating into terminals routinely speak credentials, internal hostnames, and stack traces. None of that belongs on someone else’s disk.
- Everyone else, eventually: even mundane dictation — calendar entries, slack drafts, half-formed product ideas — leaks intent. Aggregated across a year of voice memos, you’ve handed your strategic priorities to a vendor.
The market answer today is “trust our enterprise tier” or “trust our SOC 2 report.” The boothrflow answer is “the audio bytes never leave the process boundary.” That’s a much harder property to violate accidentally.
Three rules
The README has them in one line each:
- 100% local by default. Audio and transcripts never leave your machine unless you explicitly turn on a cloud BYOK provider.
- Tiny footprint. Tauri 2 + Rust. Target: ~30MB installer, ~80MB RAM idle.
- Persistent, searchable memory. Every dictation goes into a local SQLite store with both lexical (FTS5) and semantic (
nomic-embed-text) search.
Privacy mode is the cross-cutting kill switch. When it’s on, it suppresses every context channel beyond the raw STT pass: no LLM cleanup, no app-context propagation, no focused-window OCR, no auto-learn correction store. The pipeline degrades gracefully to the raw Whisper transcript.
The hot path
hotkey press (Ctrl+Win / Ctrl+Cmd)
│
▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Listen Pill │ ←─ │ tray status │ │ cpal capture│
│ shown │ │ → listening│ │ (16kHz mono)│
└─────────────┘ └─────────────┘ └──────┬──────┘
▼
┌─────────────────────┐
│ Silero VAD → Whisper│
│ or Parakeet TDT │
└──────────┬──────────┘
▼
┌─────────────────────┐
│ LLM cleanup (Qwen) │
│ via OpenAI-compat │
└──────────┬──────────┘
▼
┌─────────────────────┐
│ ClipboardInjector │
│ snapshot+paste+rest │
└──────────┬──────────┘
▼
─── focused app ───
Every cross-cutting subsystem (AudioSource, Vad, SttEngine, LlmCleanup, Injector, ContextDetector) is a Rust trait with a fake implementation behind --features test-fakes (the default, fast inner loop) and a real one behind --features real-engines. Tests don’t depend on the Windows Audio stack or Whisper being installed — which is why CI lands in ~3 minutes instead of dragging through a whisper.cpp compile.
The frontend is Svelte 5 with a strict three-layer split (pure services → TanStack Query → UI components). Types cross the Rust↔TS boundary via specta + tauri-specta, so the command surface is compile-time-checked end to end.
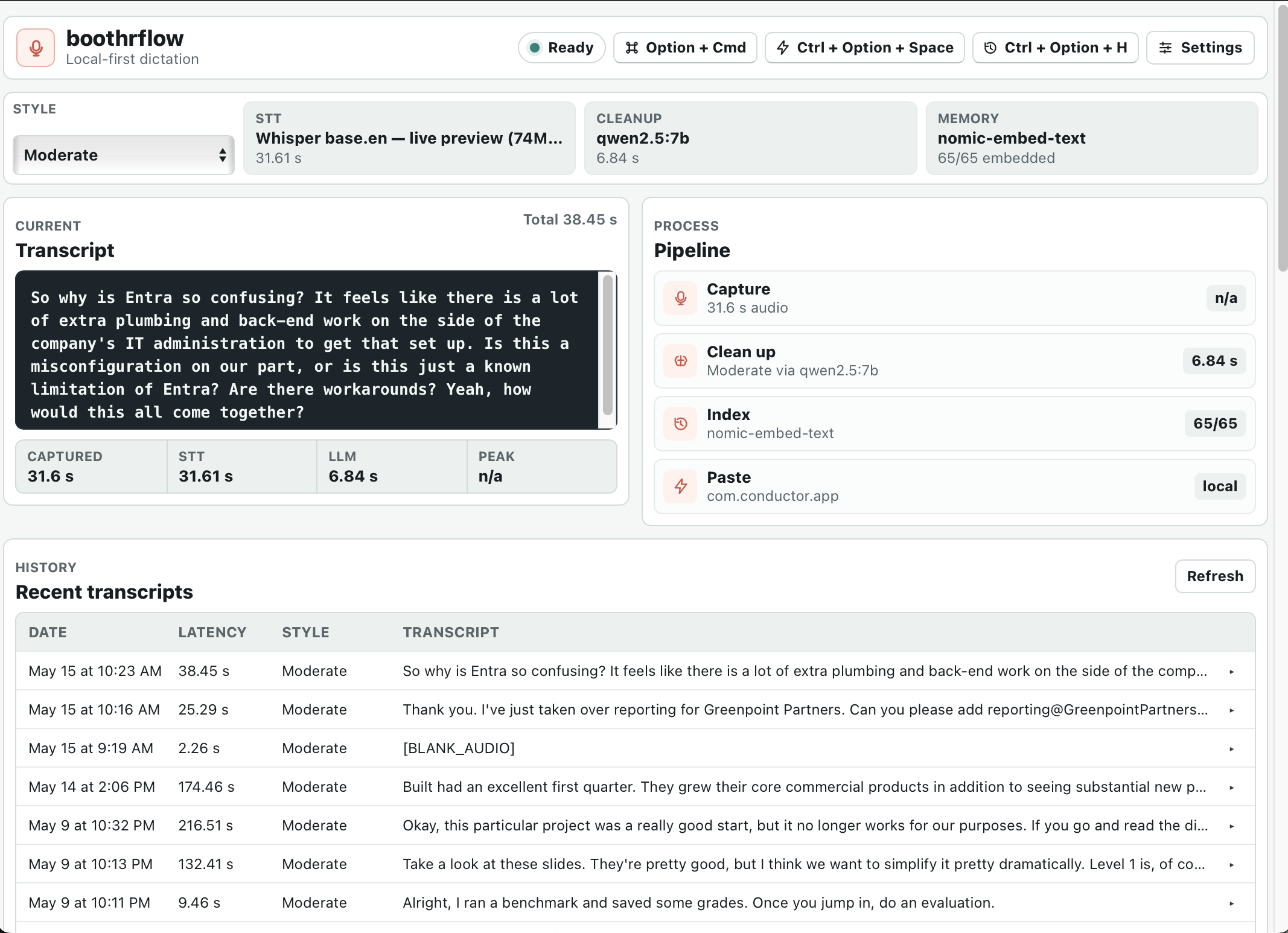
Performance metrics
Numbers from the bench harness on Apple Silicon, post-warmup (the warmup pass loads the engine once per config and runs a throwaway 1-second silence transcription before the timed call — without it, whichever engine ran first paid the model-load cost and looked ~10× slower than the others).
Speech-to-text — decode time after warmup
- Whisper tiny.en (Metal) ·
~770 ms· ~75 MB on disk · default; fast, occasionally fumbles proper nouns - Whisper base.en (Metal) ·
~850 ms· ~142 MB · noticeably better on named entities - Whisper small.en (Metal) ·
~1.5 s· ~466 MB · sweet spot for accuracy on Apple Silicon - Parakeet TDT 0.6B v2-int8 ·
~470 ms(warm) · ~600 MB · only engine that got every named entity + verb right on the Lysara capture
A note on the Parakeet number, because it’s the part of the story I got wrong the first time: an early bench measured Parakeet at 13.5s on a 116-second capture, and I took that at face value. That number was an artifact of the bench harness loading the engine fresh on every invocation — it was load + decode, not decode. The warmup pass in 4ba7e95 revealed the real cost: ~470 ms of decode, in the same order of magnitude as the Whisper variants. There’s still some structural ONNX-runtime overhead vs. whisper.cpp, but it’s nothing like an order of magnitude.
LLM cleanup — Apple Silicon via Ollama, OpenAI-compatible HTTP
- qwen2.5:1.5b ·
1.4–3.1 s· ~1 GB · ~3× faster than 7b; occasionally drops trailing content on long utterances - qwen2.5:7b ·
4.0–8.8 s· ~5 GB · default; stays comfortably below the perceived-latency threshold because you’ve finished speaking by then
The cleanup chip in the pill surfaces tok/s alongside ms, so users can diagnose a slow box without me having to instrument anything for them. Prompt-prefix caching via Ollama’s keep_alive: 5m keeps the model and its KV cache resident across dictations — the second and subsequent runs in a 5-minute window skip the load cost.
Installer / runtime budget
- Installer (Tauri 2) · target ~30 MB
- Resident RAM at idle · target ~80 MB
- Whisper tiny.en (bundled default) · ~75 MB on disk
- Parakeet TDT 0.6B (optional) · ~600 MB on disk
- Qwen 2.5 7B (optional, via Ollama) · ~5 GB on disk
Everything past the installer is opt-in or replaceable. The 7B model is the heaviest line item by far, and pnpm ollama:pull:fast skips it for tight-disk machines.
Accuracy iterations
The accuracy story has three chapters so far.
Chapter 1: Whisper tiny.en is the default for a reason — and also not the right answer. ADR-014 settled this: keep tiny.en as the bundled default so first-run is cheap, but recommend small.en for anyone who cares about quality. The UI’s STT chip reads the active model name from the daemon, so users who upgrade actually see what they’re running. On the Lysara capture, tiny.en rendered “LISAR” and converted “paste” to “pay” semantically; base.en got “Lysara” right but still kept “pay”; only Parakeet got both right.
Chapter 2: Parakeet TDT 0.6B is the most accurate engine in the stack, and after the bench harness was fixed, it’s not meaningfully slower either. Wave 6 Phase 1 (Nemotron Speech Streaming via sherpa-onnx) and Phase 2 (parakeet.cpp evaluation with Metal acceleration) still target the live-preview gap — Parakeet doesn’t emit streaming partials the way Whisper does — but the “is it too slow to be default?” question got answered the moment warmup landed. Until those phases ship, Parakeet stays opt-in behind the parakeet-engine Cargo feature.
Chapter 3: the LLM cleanup style is one knob, not five. The original Style enum was tone-based (casual / formal / very-casual / excited). Empirically, nobody switches tone — they pick one, forget the picker, and what they actually want to vary is “leave my words alone” vs “organize them for me.” Wave 6 Phase 0 replaced it with a single structuring-aggressiveness axis: Raw / Light / Moderate / Assertive, with Captain’s Log retained as an orthogonal fun preset.
The Assertive prompt got rewritten twice. The first version invented ### Section headers when the speaker had no transitions, fabricated Hi <name>... Best, [Your Name] Mail signatures in non-Mail contexts, and let small models prefix replies with "Sure, here is the formatted text:". The second version makes every structuring permission strictly conditional on its trigger (transition cues, listing cues, Mail-app context), bans the anti-patterns explicitly, and auto-upgrades qwen 0.5b/1.5b/3b → qwen 7b for Assertive only — small models can’t follow the nuanced rules but are fine for Light/Moderate/Raw.
Two other accuracy mechanisms worth calling out:
- Common mishearings editor. Settings → Voice → Recognition has a wrong-→-right substitution table. Pairs land in the cleanup prompt’s
<USER-CORRECTIONS>block as authoritative. The auto-learn coordinator can extend this list after paste: it watches the focused field for ~8 seconds (via macOS Accessibility API), and on a small single-word edit, records the pair intocommonly_misheardautomatically. FIFO-capped at 50 entries, suppressed under privacy mode. - Focused-window OCR cleanup context. macOS Vision (
CGDisplayCreateImage+VNRecognizeTextRequest) reads on-screen text and feeds it to the cleanup prompt as supporting context for disambiguating names, model IDs, and file paths. Eager Screen Recording permission prompt at toggle time. OCR text is sanitized against prompt-injection (<and>neutralized to U+2039 / U+203A) so an attack string can’t close the<WINDOW-OCR-CONTENT>block and inject fake instructions.
How I actually use it
Daily-driver patterns at this point:
- Long-form drafting. Hold-to-talk into Notion, Obsidian, or a markdown file. Assertive style. The 7B cleanup lands in 4-8s, which is faster than re-reading what I just wrote anyway.
- Slack and iMessage. Light style. Quick utterances, paragraph kept as-is. Tap-to-toggle hands-free mode (
Ctrl+Alt+Space/Ctrl+Option+Space) when I’m pacing. - Code dictation. Raw style, no cleanup. The pill prints exactly what Whisper heard, which matters when I’m dictating an identifier into a terminal.
- Searchable history. Every dictation lands in SQLite with both FTS5 and
nomic-embed-textvectors. Quick-paste palette (Ctrl+Alt+H/Ctrl+Option+H) lets me re-paste anything from history without scrolling — type two words and the right entry surfaces. - Dev mode bench harness.
BOOTHRFLOW_DEV=1unlocks captures-to-disk and the in-app Benchmarks tab.bench:replayfans the same wav out across (STT × LLM × style) and emits a leaderboard. Without this, every “is engine X better?” was a vibes call — now it’s a grade.
The bench harness is also how I caught a 10× cold-start ordering bias: the first-tested engine ate the model-load cost and looked 10× slower than the others. The warmup pass landed in 4ba7e95 — one throwaway 1-second silence transcription per engine before the timed run.
Where it’s going
Three waves queued up:
Wave 6 — engine + formatting (active branch feat/wave-6-engine-and-formatting). Phase 0 (style overhaul) has shipped. Phase 1 brings Nemotron Speech Streaming via sherpa-onnx — same param scale as Parakeet but cache-aware streaming at 80–1120 ms chunks, which closes the live-preview gap during dictation. Phase 2 evaluates parakeet.cpp on Apple Silicon (C++ Parakeet with Metal); swap on macOS only if it wins meaningfully on load + decode. Phase 3 hardens the bench harness: N=3 + median + variance + aggregate “across all captures” leaderboard.
Wave 7 — production polish (six phases, 6–9 days). The boring-but-load-bearing stuff: GitHub Actions matrix build → macOS signing + notarization → auto-update via tauri-plugin-updater → Windows signing (Azure Trusted Signing path) → first-run onboarding wizard → beta/stable channels. The macOS signing + auto-update have to ship together; unsigned auto-update is broken UX because every update re-triggers Gatekeeper’s “Open Anyway” dance.
Wave 8 — connectors, UI rebuild, privacy audit. A Connector trait + Obsidian vault push + custom HTTP webhook + Slack incoming webhooks, with voice-triggered routing (“push this to Slack” detected inline). A hyper-modern UI pass — pill redesign, Liquid Glass vibrancy on macOS, Cmd-K palette. And a PRIVACY_AUDIT.md with a pre-written AI-assistant verification prompt, default-features checklist, BYOK callouts, and a pass/fail table — so the privacy claim is auditable, not aspirational.
And further out: an iOS companion that isn’t trying to replicate the desktop’s push-to-talk magic (iOS won’t let you anyway). Instead, a private capture surface for the same searchable corpus — on-device STT (WhisperKit / sherpa-onnx via CoreML), on-device cleanup (Apple Intelligence’s FoundationModels or MLX-hosted Qwen), and end-to-end encrypted sync with user-hosted keys, Signal-style. Nobody in the dictation space ships E2E sync with keys the vendor can’t read. We will. I’d like to have a locally-hostable headless API mode as well, so you can build your own applications on top of it (e.g., a local IDE + coding LLM, etc.).
Try it
It’s a public repo, Apache 2.0:
git clone https://github.com/ebootheee/boothrflow
cd boothrflow
pnpm install
pnpm download:model:mac # Whisper tiny.en, ~75MB
pnpm ollama:pull # qwen2.5:7b + 1.5b fallback + nomic-embed-text
pnpm dev # macOS — pnpm dev:msvc on Windows
First boot compiles whisper.cpp from C++ source. Metal is auto-enabled on Apple Silicon (5–15× the CPU baseline). Hold Ctrl+Cmd (mac) or Ctrl+Win (Windows) and talk into TextEdit / Notepad. Text pastes.
Issues, ideas, PRs — all welcome at github.com/ebootheee/boothrflow.